
当前课程知识点:人工智能 > 4.计算智能 > 4.3进化计算 > 4.3.2遗传算法
1.遗传算法的基本概念
遗传算法的基本思想是从初始种群出发,采用优胜劣汰、适者生存的自然法则选择个体,并通过杂交、变异来产生新一代种群,如此逐代进化,直到满足目标为止。遗传算法所涉及到的基本概念主要有以下几个:
种群(Population):种群是指用遗传算法求解问题时,初始给定的多个解的集合。遗传算法的求解过程是从这个子集开始的。
个体(Individual):个体是指种群中的单个元素,它通常由一个用于描述其基本遗传结构的数据结构来表示。例如,可以用0、1组成的长度为l的串来表示个体。
染色体(Chromos):染色体是指对个体进行编码后所得到的编码串。染色体中的每1位称为基因,染色体上由若干个基因构成的一个有效信息段称为基因组。
适应度(Fitness)函数:适应度函数是一种用来对种群中各个个体的环境适应性进行度量的函数。其函数值是遗传算法实现优胜劣汰的主要依据
遗传操作(Genetic Operator):遗传操作是指作用于种群而产生新的种群的操作。标准的遗传操作包括以下3种基本形式:
选择(Selection) 交叉(Crosssover) 变异(Mutation)
2. 遗传算法的基本结构
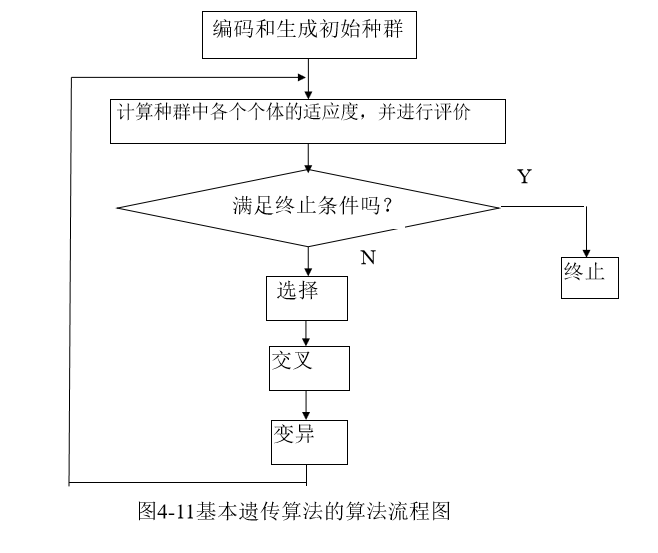
遗传算法主要由染色体编码、初始种群设定、适应度函数设定、遗传操作设计等几大部分所组成,其算法主要内容和基本步骤可描述如下:
(1) 选择编码策略,将问题搜索空间中每个可能的点用相应的编码策略表示出来,即形成染色体;
(2) 定义遗传策略,包括种群规模N,交叉、变异方法,以及选择概率Pr、交叉概率Pc、变异概率Pm等遗传参数;
(3) 令t=0,随机选择N个染色体初始化种群P(0);
(4) 定义适应度函数f(f>0);
(5) 计算P(t)中每个染色体的适应值;
(6) t=t+1;
(7) 运用选择算子,从P(t-1)中得到P(t);
(8) 对P(t)中的每个染色体,按概率Pc参与交叉;
(9) 对染色体中的基因,以概率Pm参与变异运算;
(10) 判断群体性能是否满足预先设定的终止标准,若不满足则返回(5)。
算法流程图如图4-11所示:
3.遗传编码
常用的遗传编码算法有霍兰德二进制码、格雷码(Gray Code)、实数编码和字符编码等。
(1)二进制编码(Binary encoding)
二进制编码是将原问题的结构变换为染色体的位串结构。在二进制编码中,首先要确定二进制字符串的长度l,该长度与变量的定义域和所求问题的计算精度有关。
例,假设变量x的定义域为[5,10],要求的计算精度为![]() ,则需要将[5,10]至少分为600000个等长小区间,每个小区间用一个二进制串表示。于是,串长至少等于20,原因是:
,则需要将[5,10]至少分为600000个等长小区间,每个小区间用一个二进制串表示。于是,串长至少等于20,原因是:
524288=![]() <600000<
<600000<![]() =1048576
=1048576
这样,对应于区间[5,10]内满足精度要求的每个值x,都可用一个20位编码的二进制串<b19,b18,…,b0>来表示。
二进制编码存在的主要缺点是汉明(Hamming)悬崖。
例如,7和8的二进制数分别为0111和1000,当算法从7改进到8时,就必须改变所有的位。
(2) 格雷编码(Gray encoding)
格雷编码是对二进制编码进行变换后所得到的一种编码方法。这种编码方法要求两个连续整数的编码之间只能有一个码位不同,其余码位都是完全相同的。它有效地解决了汉明悬崖问题,其基本原理如下:
设有二进制串b1,b2,…,bn,对应的格雷串为a1,a2,…,an,则从二进制编码到格雷编码的变换为:
![]()
其中,⊕表示模2加法。而从一个格雷串到二进制串的变换为:
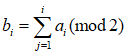
例,十进制数7和8的二进制编码分别为0111和1000,而其格雷编码分别为0100和1100。
(3) 实数编码(Real encoding)
实数编码是将每个个体的染色体都用某一范围的一个实数(浮点数)来表示,其编码长度等于该问题变量的个数。 这种编码方法是将问题的解空间映射到实数空间上,然后在实数空间上进行遗传操作。由于实数编码使用的是变量的真实值,因此这种编码方法也叫做真值编码方法。 实数编码适应于那种多维、高精度要求的连续函数优化问题。
4. 适应度函数
适应度函数是一个用于对个体的适应性进行度量的函数。通常,一个个体的适应度值越大,它被遗传到下一代种群中的概率也就越大。
(1) 常用的适应度函数
在遗传算法中,有许多计算适应度的方法,其中最常用的适应度函数有以下两种:
① 原始适应度函数
它是直接将待求解问题的目标函数f(x)定义为遗传算法的适应度函数。例如,在求解极值问题
![]() 时,f(x)即为x的原始适应度函数。
时,f(x)即为x的原始适应度函数。
采用原始适应度函数的优点是能够直接反映出待求解问题的最初求解目标,其缺点是有可能出现适应度值为负的情况。
② 标准适应度函数
在遗传算法中,一般要求适应度函数非负,并其适应度值越大越好。这就往往需要对原始适应函数进行某种变换,将其转换为标准的度量方式,以满足进化操作的要求,这样所得到的适应度函数被称为标准适应度函数fNormal(x)。例如下面的极小化和极大化问题:
极小化问题
对极小化问题,其标准适应度函数可定义为:
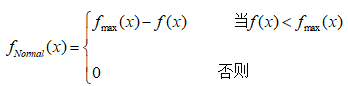
其中,fmax (x)是原始适应函数f(x)的一个上界。如果fmax (x) 未知,则可用当前代或到目前为止各演化代中的f(x)的最大值来代替。可见, fmax (x) 是会随着进化代数的增加而不断变化的。
极大化问题
对极大化问题,其标准适应度函数可定义为:
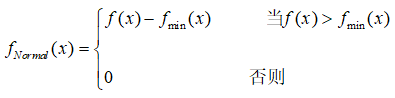
其中,fmin(x)是原始适应函数f(x)的一个下界。如果fmin(x) 未知,则可用当前代或到目前为止各演化代中的f(x)的最小值来代替。
(2) 适应度函数的加速变换
在某些情况下,适应度函数在极值附近的变化可能会非常小,以至于不同个体的适应值非常接近,使得难以区分出哪个染色体更占优势。对此,最好能定义新的适应度函数,使该适应度函数既与问题的目标函数具有相同的变化趋势,又有更快的变化速度。
适应度函数的加速变换有两种基本方法
① 线性加速
适应度函数的定义如下:
f’(x)=αf(x)+β
其中,f(x)是加速转换前的适应度函数; f’(x)是加速转换后的适应度函数; α和β是转换系数。
② 非线性加速
幂函数变换方法
f’(x)=f(x)k
指数变换方法
f’(x)=exp(-βf(x))
5. 基本遗传操作
遗传算法中的基本遗传操作包括选择、交叉和变异3种,而每种操作又包括多种不同的方法,下面分别对它们进行介绍。
(1) 选择操作
选择(Selection)操作是指根据选择概率按某种策略从当前种群中挑选出一定数目的个体,使它们能够有更多的机会被遗传到下一代中。
常用的选择策略可分为比例选择、排序选择和竞技选择三种类型。
① 比例选择
比例选择方法(Proportional Model)的基本思想是:各个个体被选中的概率与其适应度大小成正比。
常用的比例选择策略包括:轮盘赌选择和繁殖池选择
②轮盘赌选择
轮盘赌选择法又被称为转盘赌选择法或轮盘选择法。在这种方法中,个体被选中的概率取决于该个体的相对适应度。而相对适应度的定义为:
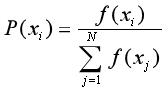
其中,P(xi)是个体xi的相对适应度,即个体xi被选中的概率;f(xi)是个体xi的原始适应度;![]() 是种群的累加适应度。
是种群的累加适应度。
轮盘赌选择算法的基本思想是:根据每个个体的选择概率P(xi)将一个圆盘分成N个扇区,其中第i个扇区的中心角为:
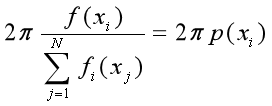
并再设立一个固定指针。当进行选择时,可以假想转动圆盘,若圆盘静止时指针指向第i个扇区,则选择个体i。其物理意义如图4-12所示:
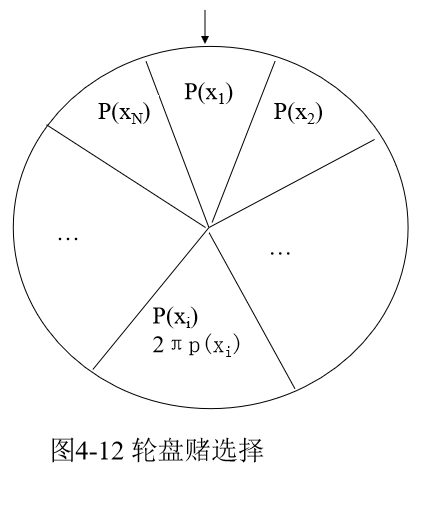
从统计角度看,个体的适应度值越大,其对应的扇区的面积越大,被选中的可能性也越大。这种方法有点类似于发放奖品使用的轮盘,并带有某种赌博的意思,因此亦被称为轮盘赌选择。
(2)交叉操作
交叉(Crossover)操作是指按照某种方式对选择的父代个体的染色体的部分基因进行交配重组,从而形成新的个体。交配重组是自然界中生物遗传进化的一个主要环节,也是遗传算法中产生新的个体的最主要方法。根据个体编码方法的不同,遗传算法中的交叉操作可分为二进制交叉和实值交叉两种类型。
①二进制交叉
二进制交叉(Binary Valued Crossover)是指二进制编码情况下所采用的交叉操作,它主要包括单点交叉、两点交叉、多点交叉和均匀交叉等方法。
单点交叉
单点交叉也称简单交叉,它是先在两个父代个体的编码串中随机设定一个交叉点,然后对这两个父代个体交叉点前面或后面部分的基因进行交换,并生成子代中的两个新的个体。假设两个父代的个体串分别是:
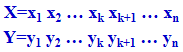
随机选择第k位为交叉点,若采用对交叉点后面的基因进行交换的方法,但点交叉是将X中的xk+1到xn部分与Y中的yk+1到yn部分进行交叉,交叉后生成的两个新的个体是:
![]()
例:设有两个父代的个体串A=0 0 1 1 0 1 和B=1 1 0 0 1 0 ,若随机交叉点为4,则交叉后生成的两个新的个体是:
A’= 0 0 1 1 1 0
B’= 1 1 0 0 0 1
两点交叉
两点交叉是指先在两个父代个体的编码串中随机设定两个交叉点,然后再按这两个交叉点进行部分基因交换,生成子代中的两个新的个体。
假设两个父代的个体串分别是:
![]()
随机设定第i、j位为两个交叉点(其中i<j<n),两点交叉是将X中的xi+1到xj部分与Y中的yi+1到yj部分进行交换,交叉后生成的两个新的个体是:
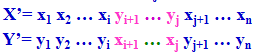
例,设有两个父代的个体串A= 0 0 1 1 0 1 和B= 1 1 0 0 1 0 ,若随机交叉点为3和5,则交叉后的两个新的个体是:
A’= 0 0 1 0 1 1
B’= 1 1 0 1 0 0
多点交叉
多点交是指先随机生成多个交叉点,然后再按这些交叉点分段地进行部分基因交换,生成子代中的两个新的个体。
假设交叉点个数为m,则可将个体串划分为m+1个分段,其划分方法是:
当m为偶数时,对全部交叉点依次进行两两配对,构成m/2个交叉段。
当m为奇数时,对前(m-1)个交叉点依次进行两两配对,构成(m-1)/2个交叉段,而第m个交叉点则按单点交叉方法构成一个交叉段。
下面以m=3为例进行讨论。假设两个父代的个体串分别是X=x1 x2 … xi … xj … xk … xn和Y=y1 y2 … yi … yj … yk … yn,随机设定第i、j、k位为三个交叉点(其中i<j<k<n),则将构成两个交叉段。交叉后生成的两个新的个体是:
![]()
例,设有两个父代的个体串A= 0 0 1 1 0 1 和B= 1 1 0 0 1 0 ,若随机交叉点为1、3和5,则交叉后的两个新的个体是:
A’= 0 1 0 1 0 0
B’= 1 0 1 0 1 1
均匀交叉
均匀交叉(Uniform Crossover)是先随机生成一个与父串具有相同长度,并被称为交叉模版(或交叉掩码)的二进制串,然后再利用该模版对两个父串进行交叉,即将模版中1对应的位进行交换,而0对应的位不交换,依此生成子代中的两个新的个体。事实上,这种方法对父串中的每一位都是以相同的概率随机进行交叉的。
例,设有两个父代的个体串A=001101和B=110010,若随机生成的模版T=010011,则交叉后的两个新的个体是A’=011010和B’=100101。即
A: 0 0 1 1 0 1
B: 1 1 0 0 1 0
T: 0 1 0 0 1 1
A’:0 1 1 1 1 0
B’:1 0 0 0 0 1
②实值交叉
实值交叉是在实数编码情况下所采用的交叉操作,主要包括离散交叉和算术交叉,下面主要讨论离散交叉(部分离散交叉和整体离散交叉) 。
部分离散交叉是先在两个父代个体的编码向量中随机选择一部分分量,然后对这部分分量进行交换,生成子代中的两个新的个体。
整体交叉则是对两个父代个体的编码向量中的所有分量,都以1/2的概率进行交换,从而生成子代中的两个新的个体。
以部分离散交叉为例,假设两个父代个体的n维实向量分别是 X=x1x2… xi…xk…xn和Y=y1y2…yi…yk…yn,若随机选择对第k个分量以后的所有分量进行交换,则生成的两个新的个体向量是:
![]()
例,设有两个父代个体向量A=23 18 17 3 19 26和B=26 23 36 17 20 5,若随机选择对第3个分量以后的所有分量进行交叉,则交叉后两个新的个体向量是:
A’= 23 18 17 17 20 5
B’= 26 23 36 3 19 26
(3) 变异操作
变异(Mutation)是指对选中个体的染色体中的某些基因进行变动,以形成新的个体。变异也是生物遗传和自然进化中的一种基本现象,它可增强种群的多样性。遗传算法中的变异操作增加了算法的局部随机搜索能力,从而可以维持种群的多样性。根据个体编码方式的不同,变异操作可分为二进制变异和实值变异两种类型。
① 二进制变异
当个体的染色体采用二进制编码表示时,其变异操作应采用二进制变异方法。该变异方法是先随机地产生一个变异位,然后将该变异位置上的基因值由“0”变为“1”,或由“1”变为“0”,产生一个新的个体。
例,设变异前的个体为A=0 0 1 1 0 1,若随机产生的变异位置是2,则该个体的第2位由“0”变为“1”。变异后的新的个体是A’= 0 1 1 1 0 1
②实值变异
当个体的染色体采用实数编码表示时,其变异操作应采用实值变异方法。该方法是用另外一个在规定范围内的随机实数去替换原变异位置上的基因值,产生一个新的个体。最常用的实值变异操作有:
基于位置的变异方法
该方法是先随机地产生两个变异位置,然后将第二个变异位置上的基因移动到第一个变异位置的前面。
例,设选中的个体向量C=2 26 39 15 20 32,若随机产生的两个变异位置分别时2和4,则变异后的新的个体向量是:
C’= 2 23 39 25 20 32
基于次序的变异
该方法是先随机地产生两个变异位置,然后交换这两个变异位置上的基因。
例,设选中的个体向量D=2 26 39 15 20 32,若随机产生的两个变异位置分别时2和4,则变异后的新的个体向量是:
D’= 2 15 39 26 20 32
-1.1人工智能的定义与发展
--人工智能的诞生
--定义
--发展
-1.2智能的本质
--人类智能
--人工的智能
-1.3人工智能各学派的认知观
--AI的萌芽
-1.4人工智能的研究与应用领域
--AI的研究范围
--AI在中国
-资源推荐
--有趣的资源
-章节习题
-2.1知识的基本概念
-2.2状态空间法
--习题
-2.3问题归约法
-2.4谓词逻辑法
-章节习题
-3.1图搜索策略
--图搜索策略概述
-3.2盲目搜索策略
-3.3启发式搜索策略
-3.4消解原理
-章节习题
-4.1概述
--计算智能定义
-4.2神经网络
-4.3进化计算
-4.4蚁群算法
-4.5模拟退火算法
-4.6博弈搜索策略
--教师讲解:博弈树
--教师讲解:剪枝
-章节习题
-5.1专家系统概述
-5.2专家系统结构
--5.4 黑板模型
-5.3专家系统的应用与发展概况
-5.4专家系统实例
-6.1机器学习的基本概念
-6.2记忆学习
-6.3归纳学习
-- 6.3.3决策树学习
-6.4解释学习
-6.5神经学习
-章节习题
-7.1自然语言理解概述
--7.1.1概述
-7.2词法分析
--词法分析
-7.3句法分析
-7.4 统计语言建模
-7.5信息检索

